nginx auth_request (3/3): Web-Application firewall, WAF
Сразу оговорюсь - я знаю про существование nginx naxsi и mod_security, речь про то, как вообще такое делается.
Под WAF я понимаю некое дополнение к веб-серверу, выполняющее одну или несколько следющих задач:
- блокировка вредоносных запросов
- подтверждение юзером "сомнительных" запросов
- ограничение частоты запросов по сложным критериям
Дополнительно можно собирать статистику.
Принцип работы всё тот же - nginx сначала пересылает копию запроса на какой-то внешний сервис и на основании ответа от этого сервиса - решает, пропускать ли исходный запрос или нет.
Механизм работы опсан в предыдущей статье, поэтому интересны прежде всего алгоритмы: 1) выделение запросов одного пользователя, 2) ограничения частоты запросов. 3) определения "вредоносности" или "подозрительности" запроса, Нетрудно заметить, третья задача зависит от первой, а вторая и третья тесно связаны.
По порядку.
Выделение запросов одного пользователя
Первая и очевидная мысль, приходящая в голову - просто смотреть запросы с одного ip. Но тут есть множество тонкостей. Случаев, когда с одного адреса могут сидеть несколько пользователей - достаточно много: nat, vpn, tor, ipv6-to-4 брокер. И обратный случай - когда один юзер может сидеть с нескольких адресов: tor.
Что делать? На заголовки полагаться нельзя, там можно подделать абсолютно всё. Комбинация ip+заголовок, например User-Agent? Это ещё хуже, подделкой заголовка можно добиться, чтобы система определяла тебя как разных юзеров, даже не меняя свой ip.
Один из возможных вариантов - заставить каждого неопознанного клиента произвоить некую ресурсоёмкую операцию, после выполнения которой этому клиенту присваивается уникальный идентификатор, который тот будет предъявлять в дальнейшем как доказательство выполненной работы. Разумеется, его нужно защитить от подделки и ограничить срок годности.
Блок схема (исходник):
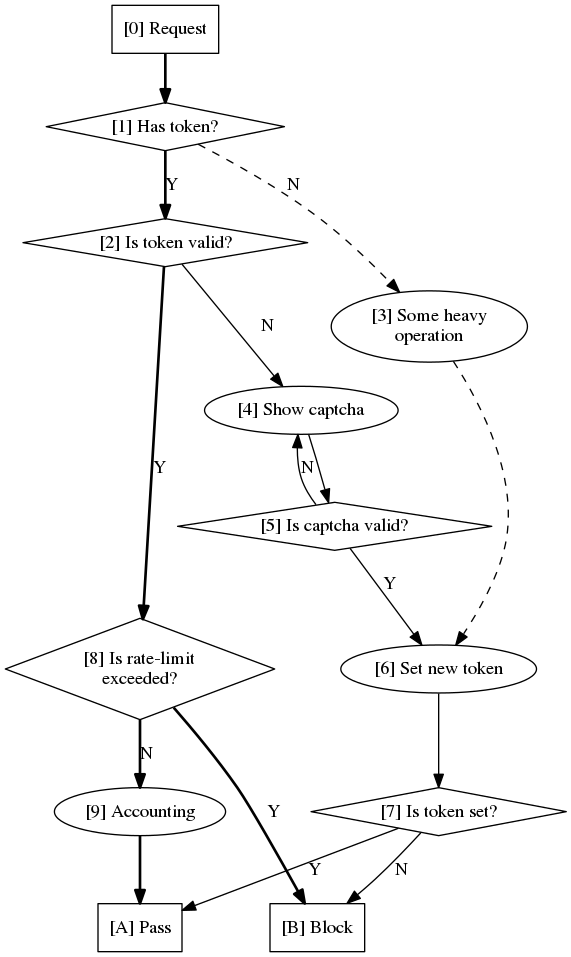
Путь "известного" юзера показан жирной линией, "неизвестного" - прерывистой. Операция (3) может быть к/либо вычислением на стороне пользователя, с сообщением результата. Или же - проверкой на робота, например следование по редиректам. сделанных средствами самого html.
Схема может изменяться в некоторых пределах, например (2) "N" может переходить не в (4), а в (3). Можно например, "неизвестных" клиентов сразу кидать на капчу, т.е. (1) "N" -> (4).
Думаю не нужно напоминать, что все операции, кроме (3) следует оптимизировать на минимальные затраты ресурсов и максимальное быстродействие. Если используется капча, её лучше нагенерить заранее и продумать механизм "карантина" на какое-то время для показанных, но не решённых.
Обратите внимание, путь по жирной линии выполняется в пределах одного обработчика.
А вот переходы к другим состояниям - требуют перехода на другие странички.
Помните, что я говорил про error_page и поддержку редиректов?
Ограничение частоты запросов
Здесь может быть куча вариантов реализации.
Например самое простое и железобетонное решение: выделять временн*ы*е слоты определённой длительности и считать запросы юзера в пределах текущего слота.
my $len = 5; # новый слот каждые 5 минут
my $time = time();
# вычисляем имя слота
my $slot = sprintf "req:%d:%d", $len, ($time - ($time % ($len * 60)));
# увеличиваем число запросов для юзера с $uuid
# и узнаём, сколько запросов он уже сделал в пределах данного слота
my $reqs = $redis->hincr($slot, $uuid => 1); # O(1)
$redis->expire($slot, 3600) if $reqs == 1;
# если $reqs >= $limit - блокируем запрос
Метод хорош тем, что крайне прост (1 запрос), хорошо масштабируется и может работать вообще без обслуживания. Основной недостаток - низкая "разрешающая способность", на границе временного слота можно превысить лимит до 2х раз.
Если нам нужна гарантия, что в каждый момент времени лимит не будет превышен, подход несколько другой. На каждого юзера заводится по персональному списку, туда пишется время запросов. Недостатки: стоимость выше, больший расход памяти.
Принцип действия такой: при частых запросах в начале очереди растёт число "недавних" запросов. Как только N-ый элемент оказывается "недавним", значит лимит превышен.
Вариант 2/а:
my ($time, $limit) = (5, 60); # время окна в минутах и количество запросов
my $now = time();
my $key = sprintf "user:%s", $uuid;
my $some = $redis->lindex($key, $limit - 1); # O(N)
my $next = $some + ($time * 60);
if ($now > $next) {
$redis->lpush($key, $now); # O(1)
# периодически подрезаем список, чтоб не разрастался сверх меры
$redis->ltrim($key, 0, $limit - 1); # O(N), где N - количество удалённых элементов
$redis->expire($key, 3600) if $some == 0;
} else {
# лимит превышен
}
Вариант 2/б, где "гарантированно дорогой" lindex() с O(N), заменяется на llen() + lindex(-1), т.е. 2 x O(1). Хотя в теории, lindex(N) для списка в котором меньше N элементов - тоже должен отрабатывать за O(1).
my ($time, $limit) = (5, 60); # время окна в минутах и количество запросов
my $now = time();
my $key = sprintf "user:%s", $uuid;
my $len = $redis->llen($key); # O(1)
if ($len < $limit) {
# первичное заполнение
$redis->lpush($key, $now); # O(1)
$redis->expire($key, 3600) if $len == 0;
return;
} else {
$redis->ltrim($key, 0, $limit - 1); # O(N), где N - количество удалённых элементов
my $last = $redis->lindex($key, -1); # O(1)
my $next = $last + ($time * 60);
if ($now >= $next) {
$redis->lpush($key, $now);
return;
}
}
# лимит превышен
Впринципе, всё это экономия на спичках. Значительно большего эффекта можно добиться, если считать не абстрактные "запросы", а прикинуть стоимость конкретного запроса в плане нагрузки и выделять пользователю "бюджет" на пользование.
Например, показ странички с картинками, где половина содержимого - статика, а остальное закешировано - это одно. Полнотекстовый поиск по сайту - это уже другое. А попытка авторизации на сайте - совсем даже третье.
"Вредоносность" и "подозрительность" запроса
Здесь сложно дать какие-то рекомендации, смотрите по ситуации. Можно анализировать заголовки (User-Agent/Referer/Accept/...), частоту запросов, их логическую взаимосвязь. Например, запрос к автодополнению с X-Requested-With - это с высокой вероятностью человек. Постоянная долбёжка поля поиска с интервалом в секунду - практически наверняка бот-дудосер. Монотонные запросы несвязанные друг с другом - поисковый бот. Пиковые всплески запросов с интервалом в несколько минут - юзер, который открывает несколько вкладок сразу, а потом сидит их читает.
Вобщем, на практке быстро научитесь на что нужно смотреть.
Ну и не стоит забывать про типовые запросы для поиска админок вордпресса, скуэля, гостевух и прочего говнокода на похапе. Клиенту, спалившемся на таком можно просто возвращать 404 на все запросы, чтоб больше не приходил.